L'algorithme prend en entrée un problème et retourne soit une solution sous forme d'une séquence d'actions à faire ou bien une notification d'échec. Le problème se définit formellement comme suit :
On va dans un premier temps modéliser le monde. Tous les états, toutes les actions, tous les arcs passant d'un état à un autre, sont mémorisés. Puis on développera des algorithmes agissant sur ce modèle-monde à l'aide d'un interface de commandes. Dans le modèle-monde les états sont appelés des noeuds.
La solution s'appelle un chemin, c'est une liste d'actions qui, si on les applique dans l'ordre à partir de l'état initial doit nous mener à un état but.
Le modèle est déterministe, c'est à dire qu'une action autorisée appliquée à un noeud ne produit qu'un seul noeud résultat.
Nous explicitons la distinction entre les arcs et les actions. Le modèle étant déterministe, une action, selon son point de départ, désigne un arc. L'action désigne alors un ensemble d'arcs définissant une fonction de l'ensemble des noeuds du graphe sur lui-même.
L'arc partant du noeud, traduit l'exécution d'une action à partir de ce noeud. Donc deux arcs partant d'un même noeud correspondent nécessairement à deux actions distinctes.
Les arcs possèdent un attribut supplémentaire désignant l'action à la quelle elles appartienent. Et il existe un ensemble de toutes les actions enviseageables.
Le passage de chaque arc a un coût; donc dans le cas général ce coût ne dépend pas seulement de l'action mais aussi du noeud de départ.
On enrichie donc la définission du graphe précédent :
Liste des actions. Liste des actions applicables sur le noeud `e`. Le noeud obtenu en appliquant l'action `a` à partir du noeud `e`. Coût à partir du noeud `e` en faisant l'action `a`. Arc correspondant à l'action `a` à partir du noeud `e`. Action auquel appartient l'arc `p`. Coût de l'arc `p`.
On redéfinit :
`G ="Grafo"(N"="10,alpha"="3,p"="0.75,s"="1)`
Crée un nouveau graphe `G` de `N` noeuds, avec un nombre d'actions `alpha`, une probabilité qu'une action soit autorisée valant `p`, et une graine de hasard `s`
Crée un arc correspondant à l'action `a` partant du noeud `x` et allant sur le noeud `y`.
Lorsqu'on crée un graphe, on utilise les paramètres `N` et `alpha` et on construit un nouveau graphe ayant les caractéristiques suivantes :
Le nombre de nœuds est égal à `N`.
La liste des actions est la liste des entiers `1,2,3,...,alpha`.
La probabilité qu'une action soit autorisée vaut `p`.
On reprogramme ces trois classes en Python, en envoyer à ChapGPT un second prompt de ce genre :
On introduit un nouveau type de donnée appelé l'action et qui est représentée par un entier. Modifit les trois classes comme suit :
La classe `"Arco"` comprend deux attributs supplémentaires :
L'attribut `"accion"` qui est l'action correspondant à l'arc.
L'attribut `"costo"` qui est le coût de l'arc.La classe `"Nodo"` comprend trois méthodes supplémentaires :
La classe `"Grafo"` comprend un attribut supplémentaire :
La méthode `"A"("self")` retourne la liste des actions possibles applicables au noeud, obtenu en parcourant la liste des arcs partants du noeud et en accumulants leur action correspondante.
La méthode `"R"("self", a)` retourne le noeud obtenue en appliquant l'action `a` au noeud.
La méthode `"C"("self", a)` retourne le coût obtenue en appliquant l'action `a` au noeud.
Dans chaque noeuds, les arcs partant correpondent nécessairement à des actions différentes.
L'attribut `"accion"` qui contient la liste des actions uttilisées dans le graphe.
Lorsqu'on crée un graphe, on utilise les paramètres `N`, `alpha`, `p`, et on construit un nouveau graphe ayant les caractéristiques suivantes :
Le nombre de nœuds est égal à `N`.
La liste des actions est la liste des entiers de `1` à `alpha`.
La probabilité qu'une action soit autorisée vaut `p`.
Les noeuds sont appelés des états.
Le modèle monde étant en place, on définit ce qu'est un problème par le cintuplet de fonctions suivant `(S,"A","R","B","C")` :
`"A"(e) = e".A"()` : Liste des actions possibles applicables sur l'état `e`.
`"R"(e,a) = e".R"(a)` : Etat résultat en appliquant l'action `a` à partir de l'état `e`.
`"C"(e,a) = e".C"(a)` : Coût de l'action `a` appliqué à l'état `e`.`S` : Etat initial
`"B"(e)` : Fonction caractéristique qui retourne vrai si l'état `e` est un but, et faux sinon.
Si le coût est constant, le problème est défini par le quadruplet `(S,"A","R","B")`.
Un chemin est une suite d'actions.
L'environnement du problème est le modèle monde. L'algorithme de résolution n'utilise que les fonctions `(S,"A","R","B")` et aucune fonction propre au modèle monde. Une solution sera un chemin dans le graphe partant de l'état initial pour aller sur un état but. La solution est dite optimale si la somme des coûts des arcs du chemin est minimale parmi toutes les solutions.
On pose 4 critère de performance des algorithmes d'exploration :
La complexité s'exprime en fonction des valeurs suivantes, et se calcul dans le pire des cas :
Et on considère des graphes ressemblant à des arbres, ce qui nous permet d'utiliser les mêmes paramètres pour exprimer les complexités en temps et en espace.
Le problème comprend :
Lorsque le nombre d'actions possibles pour un état est supposé fini, et davantage encore, lorsqu'il est supposé d'une grandeurr raisonnable telle que la boucle listant toutes ses actions reste une opération de complexité négligeable devant celle de l'algorithme dans son ensemble. La procédure est la suivante :
EXPLORER-ARBRE(`S,"A","R","B"`) :
Si l'état initial est un but alors retourner le chemin vide.
Initialiser la frontière avec l'état initial.
Répéter indéfiniment :
Si la frontière est vide alors retourner échec.
Choisir un état dans la frontière, et le retirer de la frontière.
Pour chaque fils de cet état :
Si c'est un but alors retourner le chemin allant à ce fils.
Ajouter ce fils dans la frontière.
Notez que si on applique cet algorithme à un graphe, dès qu'il repasse sur un état déjà exploré, il boucle indéfiniment.
On mémorise l'ensemble des états déjà explorés pour éviter de les explorer plusieurs fois. On ajoute 3 instructions (notées en rouge) à l'algorithme d'exploration générale d'un arbre :
EXPLORER-GRAPHE(`S,"A","R","B"`) :
Si l'état initial est un but alors retourner le chemin vide.
Initialiser la frontière avec l'état initial.
Initialiser l'ensemble exploré à vide.
Répéter indéfiniment :
Si la frontière est vide alors retourner échec.
Choisir un état dans la frontière, et le retirer de la frontière.
Ajouter l'état à l'ensemble exploré.
Pour chaque fils de cet état :
Si c'est un but alors retourner le chemin allant à cet état
Si il n'est ni dans la frontière ni dans l'ensemble exploré alors ajouter cet état dans la frontière
Dés que l'on commence à explorer un état de la frontière, on le retire de la frontière pour le mettre dans l'ensemble exploré. La frontière est l'ensemble des états atteints mais non encore explorés. L'ensemble exploré est l'ensemble des états déjà explorés ou en cours d'exploration.
On programme l'algorithme `"EXPLORER-GRAPHE"(S,"A","R","B")` en Python, simplement en envoyer à ChapGPT un troisième prompt comme suit, et il distingue bien le modèle monde, de l'algorithme qui n'utilise comme interface de commande que les seules fonctions `S,"A","R","B"` définies avec le problème. :
On programme un algorithme adapté aux graphes. Les noeuds sont appelés des états.
On définit 2 fonctions `A,R` :
`A(e)=e".A"()` qui donne la liste des actions possibles applicables sur l'état `e`.
`R(e,a)=e".R"(a)` : qui donne l'état résultat en appliquant l'action `a` à partir de l'état `e`.Un état possède une liste d'actions possibles qui appliquée à l'état retourne une liste d'états résultats appelés états fils.
Un chemin est une liste d'actions.
La frontière est l'ensemble des états à traiter.
L'ensemble exploré est l'ensemble des états déjà explorés (ou en cours d'exploration).
L'état initial est `S`
La fonction caractéristique `"B"(e)` retourne vrai si `e` est un état but, et faux sinon.
L'algorithme `"EXPLORER-GRAPHE"(S,"A","R","B")` est décrit comme suit :
`"EXPLORER-GRAPHE"(S,"A","R","B")` :
Peut-tu programmer cet algorithme en utilisant seulement les fonctions `S,"A","R","B"` et pas celle des classes `"Grafo"`, `"Nodo"`, `"Arco"` qui représentent le modèle monde ?
Si l'état initial est un but alors retourner le chemin vide.
Initialiser la frontière avec l'état initial.
Initialiser l'ensemble exploré à vide.
Répéter indéfiniment :
Si la frontière est vide alors retourner échec.
Choisir un état dans la frontière, et le retirer de la frontière.
Ajouter l'état à l'ensemble exploré.
Pour chaque fils de cet état :
Si c'est un état final alors retourner le chemin allant à ce fils.
Si il n'est ni dans la frontière ni dans l'ensemble exploré alors ajouter cet état dans la frontière.
Jusqu'à présent, l'instruction « Choisir un état dans la frontière, » ne précise pas la façon dont est fait ce choix.
On utilise la frontière comme une file. ChatGPT le propose d'emblé :
" Voici une première version simple, en parcours en largeur, c’est-à-dire que la frontière est utilisée comme une file. "
Il convient donc de trouver les notations formelles les plus pratiques pour exprimer le retrait d'une donnée dans une file, et l'écriture d'une donnée dans une file.
Le parcours du graphe en largeur d'abord nous assure :
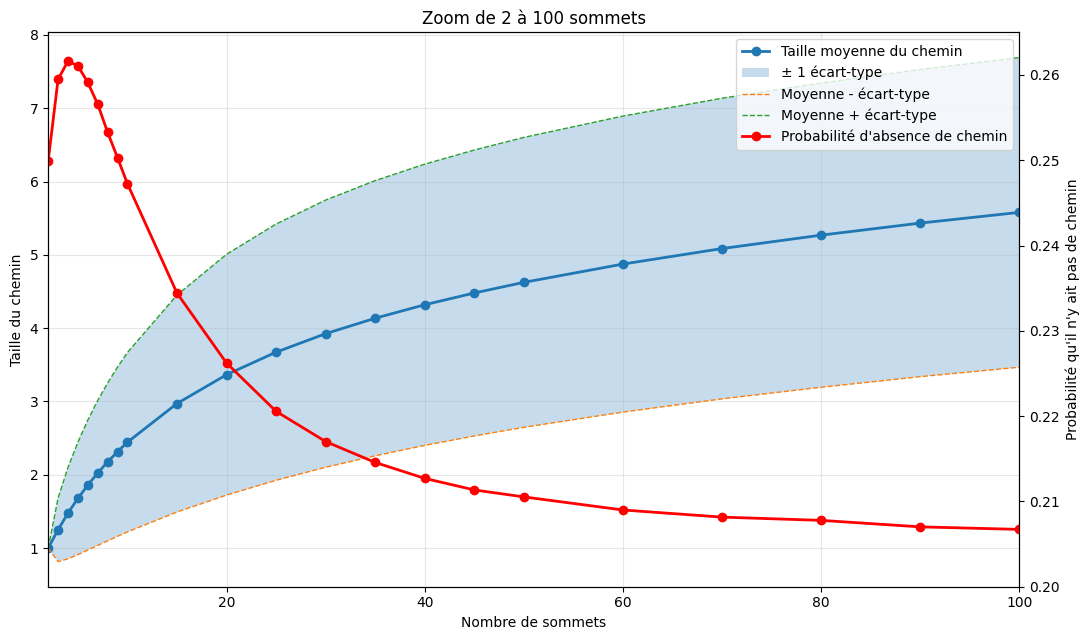
Il est alors possible d'établir des statistiques empiriques sur la connexité, et la longueur des chemins optimums, dans un graphe binaire au hasard, et de vérifier si cela correspond bien aux valeurs théorique.
Programme le calcul statistique (probabilité d'absence de chemin, moyenne des longueur de chemins, écart-type des longueurs de chemin) comme suit :
TEST(N, NS=100, na=2, p=1, n1=1, n2=1)
k0=0
k1=0
L=0
L2=0
Pour la graine i variant de 1 à 1+ NS :
G=Grafo(N,na,p,i)
S regroupe les n1 premiers noeuds dans G.nodo
B regroupe les n2 noeuds suivants dans G.nodo
Z=EXPLORER_GRAPHE(S,A,R,B)
si Z==None alors k0=k0+1
sinon
k1=k1+1
L = L + len(Z) - 1
L2=L2 + (len(Z) - 1)**2
Si k1==0 alors retourne [1,None,None]
Si k1==1 alors retourne [k0/(k0+k1),L/k1,None]
Retourne [k0/(k0+k1), L/k1, math.sqrt(L2/(k1-1) - (L/k1)**2)]
Faite le calcul sur 10 000 000 graphes binaires au hasard. Puis demander à CHatGPT de faire un shéma récapitulant les résultats :
On utilise la frontière comme une pile.
Il convient donc de trouver les notations formelles les plus pratiques pour exprimer le retrait d'une donnée dans une pile, et l'écriture d'une donnée dans une pile.
On se limite aux chemins de longueur `l`. On ajoute le paramètre d'entrée `l` et on ne dépasse pas la taille des chemin au delà de `l`.
Le parcours du graphe en profondeur limitée nous assure :
On explore en profondeur d'abord de façon limité à `l` puis on incrémente `l` et on recommence.
Le parcours du graphe en profondeur itérative d'abord nous assure :
Remarque : La complexité est la même que précédement car `O(1"+"b"+"b^2"+"b^3"+"..."+"b^d) = O(b^d)`
La recherche bidirectionnelle part à la fois, de l’état initial vers le but, et du but vers l’état initial. L’idée est que deux recherches de profondeur `d"/"2` coûtent beaucoup moins cher qu’une seule recherche de profondeur `d`.
Mais cela nécessite d'avoir un jeu d'actions inverses. On complète le model-monde comme suit : Le graphe doit considérer la possibilité de parcourir ses arcs dans le sens inverse, et donc doit construire un jeu d'actions inverse. On ajoute à la classe des arcs un nouvel attribut désignant l'action inverse correspondante, et pour chaque noeud on attribut chaque arc entrant sur le noeud à une actions inverses distinctes pour le noeud.
Une fois le modèle monde mis en place, on définit ce qu'est un problème d'exploration bidirectionnelle par le cintuplet de fonctions suivant `(S,"A","R","inv","A_","R_",B)` où `S` est l'état initial et `B` est l'état final :
`"A_"(e)` |
L'ensemble des actions inverses possibles applicables à l'état `e`. |
`"R_"(e,a)` |
L'état obtenu en appliquant l'action inverse `a` à partir de l'état `e`. |
`"inv"(e,a)` |
Retourne l'action inverse correspondant à l'arc sortant de `e` et d'action `a`. |
Le parcours du graphe nous assure :
Le coût d'un état `X` est le coût du chemin le moins couteux partant d'un état initial pour aller sur `X`. On note `g(X)`, le coût pour atteindre le noeud `X`
La frontière est une file ordonnée selon le coût
EXPLORER-COÜT-UNIFORME-(`S,"A","R","B","C"`) :
Si l'état initial est un but alors retourner le chemin vide.
Initialiser la frontière avec l'état initial.
Initialiser l'ensemble exploré à vide.
Répéter indéfiniment :
Si la frontière est vide alors retourner échec.
Choisir un état dans la frontière avec le coût le plus faible, et le retirer de la frontière.
Si c'est un but alors retourner le chemin allant à cet état
Ajouter l'état à l'ensemble exploré.
Pour chaque fils de cet état :
Calculer son coût
Si il n'est ni dans la frontière ni dans l'ensemble exploré alors ajouter cet état dans la frontière
Si il est dans la frontière avec un coût plus élevé, alors remplacé son coût par l'autre coût plus faible.
Il convient donc de trouver les notations formelles les plus pratiques pour exprimer le retrait et l'écriture d'une donnée dans une liste ordonnée.
`C"*"` : Coût du chemin optimal vers un noeud but.
`epsilon` : Coût minimum de chaque action.
Complétude : oui.
Optimalité : oui.
Compléxité en temps : `O(b^(1+"floor"((C"*")/epsilon)))`
Compléxité en espace : idem
Nous avons une fonction d'évaluation `f`. Pour chaque état `X`, l'évaluation `f(X)` indique un niveau de désintérêt.
La recherche par le meilleur d'abord passe d'abord par les états d'évaluation les plus faibles.
La frontière est une file ordonnée selon cet évaluation.
`h(X)=` coût estimé du chemin le moins couteux partant de `X` pour aller sur un état but.
`h(X)>=0` et si `X` est un but alors `h(X)=0`
On choisit comme fonction d'évaluation, l'estimation du coût :
`f(X)=h(X)`
Complétude : non (sauf si nombre de noeux fini).
Optimalité : non.
Compléxité en temps : `O(b^m)`
Compléxité en espace : idem
L'heuristique `h` est admissible si elle ne surestime jamais le coût pour atteindre le but. La valeur `h(X)` ne doit jamais être supérieur au coût réel du meilleur chemin partant de `X` pour allez sur un état but.
L'heuristique `h` est consistante si quelques soient un état `X` et une action autorisée `a` nous avons l'inégalité suivante :
`h(X)<=C(X,a)+h(R(X,a))`
L'estimation doit être inférieure ou égale aux estimations fils dans lesquelles on a ajouter le coût de l'action. Supposons donc que `Y` soit un successeur de `X`, et que `C` soit le cout de l'arc passant de `X` à `Y`, autrement dit, `Y"="R(X,a)`, `C"="C(X,a)`. Alors nous devons avoir : `h(X)<=C+h(Y)` ou autrement dit :
`h(X)-h(Y)<=C`
Exemple : La distance à vole d'oiseaux est une heuristique consistante pour estimer la distance par la route.
`h` est une heuristique consistante `=>` `h` est une heuristique admissible
`f(X) = g(X)+h(X)`
`g(X)` : coût pour aller d'un état initial à l'état `X`.
`h(X)` : coût estimé pour aller de l'état `X` à un état but (`h(X)"="0` si `X` est un état but).
`f(X)` : coût estimé pour aller d'un état initial à un état but en passant par l'état `X`.
On note `h"*"(X)` le coût réel pour aller de l'état `X` à un état but. Une heuristique `h(X)` est dite admissible si elle ne surestime jamais le coût réel pour atteindre le but. `h(x)<=h"*"(X)`
Elle est dite consistante si elle obéït à l'inégalité triangulaire basé sur un arc avec son coût réel. `h(X)<=C(X,a)+h(R(X,a))`
Optimalité A* exploration arbre : oui si `h` est admissible.
Optimalité A* exploration graphe : oui si `h` est consistant.
Preuve par l'absurde. Considérons le but optimale `B` et un second but non-optimal `B_2`. Donc :
`g(B) < g(B_2)`
L'évaluation`f` dans une exploation A* est :
`f(X) = g(X)+h(X)`
Comme `B` et `B_2` sont des buts, `h(B)"="0` et `h(B_2)"="0`
`f(B)=g(B)+h(B)`
`f(B)=g(B)`
Si l'algorithme abouti à `B_2` alors à l'étape d'avant, il contient `B_2` dans la frontière. Puisqu'il y a d'autres états buts et que l'algorithme de parcours de l'arbre est complet, il y aura forcement aussi dans la frontière un état `A` se trouvant sur le chemin allant de la racine au but `B`. On note le coût réel pour aller d'un état `X` à un état but, `h"*"(X)`. Comme `A` est sur le chemin allant au but `B` :
`g(B)=g(A)+h"*"(A)`
`f(B)=g(A)+h"*"(A)`
D'autre part l'évaluation`f` appliquée à A donne :
`f(A) = g(A)+h(A)`
L'heuristique `h` étant admissible, `h(X) <= h"*"(X)` , donc
`f(A)<= f(B)`
Et l'algorithme choisira toujours cet autre état `A` plus-tôt que l'état `B_2`.
En conclusion l'exploration A* doit retourner une solution optimale. CQFD
Si l'heuristique consistance, démontrons d'abord que l'évaluation est monotone `f(X)<=f(R(X,a))` :
Supposons donc que `Y` soit un successeur de `X`, et que `C` soit le cout de l'arc passant de `X` à `Y`, autrement dit, `Y"="R(X,a)`, `C"="C(X,a)`.
L'heuristique `h` est consistante :
`h(X)<=C+h(Y)`
`g(X)+h(X) <= g(X) + C +h(Y)`
`f(X) <= g(Y) +h(Y)`
`f(X) <= f(Y)`
CQFD
Maintenant démontrons que chaque fois que l'algorithme A* choisit un noeud `X` à développer, le chemin optimal entre un noeud initial et le noeud `X` a été trouvé. Supposont que ce ne soit pas le cas. Alors il devrait exister un autre noeud `Y` dans la frontière appartenant à un chemin optimal entre un noeud initial et `X`.
Mais la fonction d'évaluation `f` est croissante ou égale le long de n'importe quel chemin, `f(Y)<=f(X)`. Donc `Y` aura été choisie avant `X`, d'où une contradiction. CQFD