si `x"="1` alors si `y"="0` alors retourne `0` si `z"="1` alors retourne `1` si `y"="1` alors retourne `1` retourne `0` |
 |
Tout problème, aussi complexe soit-il, soumis à notre analyse, se ramène à des sous problèmes élémentaires transcris dans un langage simple et obéissant à une logique triviale. Notre esprit étant limité, il ne serait pas capable d'analyser un problème complexe sans le diviser en parties plus simples. Et la rigueur mathématique nous oblige à utiliser une logique totalement vérifiable et objective, donc triviale. C'est pourquoi la construction de la logique commence par le calcul booléen, le plus simple des calculs.
Et c'est aussi pourquoi l'informatique commence par le calcul booléen. On revisite donc la conception des langages de programmation à partir du calcul booléen, pour aboutir à une définition quasi-naturelle de l'informatique en tant que science du calcul.
Un connecteur booléen d'arité `n` est une application de `{0,1}^n→{0,1}`. Il y a donc `2^(2^n)` connecteurs `n`-aire différents.
Un connecteur booléen d'arité `n` est dit dégénéré s'il existe une de ses entrées qui ne transmet jamais d'information sur le résultat. Dans ce cas, l'entrée en question peut être enlevée et le connecteur peut d'être défini avec une arité `n"-"1`.
Il y a 4 connecteurs unaires dont 2 non-dégénérés notés :
Il y a `16` connecteurs binaires dont `10` non-dégénérés notés :
Pour simplifier l'écriture, on note les entrées `x,y,z,t,...` au lieu de `x_1,x_2,x_3,x_4,...`. Le connecteur `0` retourne `0` quelque soit ses entrées. Le connecteur `x` retourne la première entrée quelque soit ses autres entrées. Le connecteur `"¬"y` retourne la négation de la seconde entrée quelque soit ses autres entrées. Etc..
Le nombre de connecteurs en fonction de l'arité croit selon une double exponentielle, `2^(2^n)`. Il y a `256` connecteurs ternaires, puis `65536` connecteurs quaternaires. Les connecteurs ternaires dégénérés s'obtiennent en parcourant les connecteurs d'arité inférieur appliqués à une partie des entrées mais dans le même ordre. Il y a `2"+"2"*"3"+"10"*"3``=``38` connecteurs ternaires dégénérés. Il y `2"+"2"*"4"+"10"*"6"+"38"*"4``=``222` connecteurs quaternaires dégénérés.
Le connecteur binaire est une application de `{0,1}^2→{0,1}`. Comment programmer son calcul de manière la plus rapide ? Par une seule instruction d'adressage indirecte désignant le résultat du calcul. Cela nécessite de faire une première fois le calcul et de mémoriser tous les résultats dans une table appelée « la table de vérité » du connecteur. Les résultats sont mémorisés dans un ordre qui correspond à un ordre de toutes les entrées possibles qui sont des `n`-uplets de booléens. On choisit l'ordre correspondant la représentation classique des entiers en binaires :
`(1)`
`(0,1)`
`(1,0)`
`(1,1)`
`(0,0,1)`
`(0,1,0)`
`(0,1,1)`
`(1,0,0)`
`(1,0,1)`
`(1,1,0)`
`(1,1,1)`...
Le connecteur est définie par sa table de vérité qui est constitué des résultats booléens mis bout à bout pour chaque entrée énumérée dans l'ordre. Le connecteur `n`-aire est donc défini par un `2^n`-uplets de booléens qui constitue sa table de vérité. Le calcul du connecteur se fait par une unique instruction, un adressage indirecte dans sa table de vérité. Puis les connecteurs, à leurs tours, peuvent être mis dans l'ordre selon la représentation classique des entiers en binaires.
Liste des connecteurs unaires :
Liste des connecteurs binaires :
Si on ne retient comme connecteur que ceux non-dégénérés :
`"∧","∨","→","←","↔", bar("∧"),bar("∨"),"↛","↚","+"`
Puis à la négation globale près :
`"∧","∨","→","←","↔"`
Puis à la permutation près des arguments :
`"∧","∨","→","↔"`
Puis à la négation près des arguments :
`"∧","+"`
Le calcul le plus rapide d'un connecteur d'arité `n` est de complexité de temps `O(1)`. Par contre, il est de complexité d'espace `O(2^n)`.
Lorsque `n` devient grand, on voudra trouver un algorithme moins couteux en mémoire. Par contre il sera plus couteux en temps. Les premiers algorithmes mis en oeuvre n'utilisent pas de boucle ni de variable intermédiaire. Il ne font que tester les entrées, aller dans des sous-programmes, et retourner `0` ou `1`. L'algorithme se résume en la composition de connecteurs d'arité plus faible. C'est la première étape dans la conception d'un langage de programmation.
On défini le langage `ccL_0` sans boucle, ni variabe intermédiaire, dont les actions possibles sont de tester les entrées, d'appeler un sous-programme (mais sans pouvoir fair de boucle), et de terminer le programme en retournant `0` ou `1`. Il ne comprend qu'un type d'instruction que l'on codifit par `A"*"B` où `A` et `B` sont des sous-programmes. L'instruction `A"*"B` teste le résultat d'un sous-programme `A`, et si ce résultat est `1` alors exécute le sous-programme `B`. La notation la plus naturelle consiste à représenter une succession d'instructions par une liste d'instructions c'est à dire séparées par des virgules et entourée de parenthèses `(...)` qui délimitent ainsi le sous-programme. Nous n'utiliserons donc pas les braquettes `{...}`, que l'on réservent pour désigner des sacs, liste dans le quel on peut permuter les éléments. Un sous-programme est soit une séquence d'instructions entourées par des paranthèses, ou soit une seule instruction parmi `0,1,x,y,z,t,...` Ces instructions terminent le sous-programme en retournant la valeur booléenne correspondante, où `x` désigne le premier argument du programme global, où `y` désigne le second argument du programme global, etc.. Ainsi par exemple :
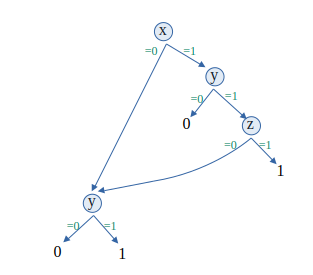
`x"*"(y"*"0,z"*"1),y"*"1,0`
Ce programme s'écrit de manière classique et sous forme d'un grapĥe orienté sans boucle (arbre avec sous-arbres partagés) :
si `x"="1` alors
si `y"="0` alors retourne `0`
si `z"="1` alors retourne `1`
si `y"="1` alors retourne `1`
retourne `0`
On peut abandonner le concept d'instructions séquencielles, et n'utiliser que la construction de paires d'instructions. Et l'on peut aussi préciser les sous-arbres partagés en les identifiant par un indice :
`x(y(0,1),y(0,z(y(0,1),1)))` `x(y_1(0,1),y(0,z(y_1,1)))`
Le langage de programation est suffisament simple pour percevoir toutes les solutions programmatives et leur différentes complexités. Le programme procède à une succession de sélections. On choisi de programmer automatiquement selon une heuristique. On teste les entrées dans un ordre : On choisi l'entrée qui procède à une disivion la plus équilibrée, c'est à dire dont la moyenne des résultats sur l'ensemble des entrées restantes est la plus proche de `1"/"2`. Et en cas d'égalité, on choisie l'ordre `x,y,z,...`. Cela défini une forme normale de complexité en temps minimal, en supposant l'équiprobabilité.
Notre recherche se veut initiée par aucune cause arbitraire autre que la simple curieusité, (dont celle du mystère essentiel, ce en quoi les mathématiques ne sont pas si étrangère aux religions). Et elle suit une doctrine qui essaye justement d'enlever l'arbitraire tout en recherchant la simplicité. De par la génèse de toute chose, on suit un ordre naturel où l'on décrit des théories simples comme fondation de théories plus compliquées.
Le contexte comprend `n` inconnus booléens, par exemple `n"="4`, notés `x,y,z,t`. Notre approche devient probabiliste et va utiliser une métrique. Un évènement est caractérisé par la valeur possibles du `n`-uplet `(x,y,z,t)`. En l'absence d'autre information, un principe ergodique pose une équiprobabilité entre tous les évènements possibles. Puis on définit la distance entre deux évènements comme étant égale au nombre de variables distinctes. Ainsi la distance entre l'évènement `(x"="1,y"="0,z"="1,t"="1)` et l'évènement `(x"="1,y"="1,z"="0,t"="0)` vaut `3`.
`d"("(1,0,1,1),(1,1,0,0)")"=3`
La logique propositionnelle enrichie de cette probabilité et de cette distance va engendrer de nouveaux concepts.
On part de l'hypothèse ergodique où toutes les configurations élémentaires sont équiprobables. Autrement dit, les variables de base `x_1,x_2,x_3,x_4,...` utilisées pour définir des configurations élémentaires sont toutes indépendantes entre elles, et chacune ont une probabilité `1"/"2`. Une variable booléenne quelconque `x` représente la valeur logique d'une proposition. On utilise la même lettre pour désigner une proposition quelconque. La probabilité d'une proposition quelconque `x` est égale au rapport du nombre de configurations élémentaires où `x` est vrai par le nombre de configurations élémentaires. On note `N` le nombre de configurations élémentaires. Si on se limite à `n` variables booléennes alors `N = 2^n`. On note `N(x)` le nombre de configurations élémentaires où la proposition `x` est vrai. On note `P(x)` la probabilité que la proposition `x` soit vrai.
`P(x) = (N(x))/N`
Considérons deux propositions `x, y` quelconques. Il découle de la règle de dénombrement suivante `|A"∪"B|=|A|+|B|−|A"∩"B|`, que :
`P(x "ou" y)=P(x)+P(y)−P(x "et" y)`
Pour la lisibilité on utilisera quelque fois les symboles `"et"`, `"ou"`, à la place de `"∧","∨"`. La probabilité conditionnelle de `x` sachant `y`, notée `P(x"/"y)`, est égale au rapport du nombre de configurations élémentaires où `x` est vrai par le nombre de configurations élémentaires où `y` est vrai. Elle n'est définie que si la probabilité de `y` n'est pas nulle. On l'étend par convention selon un même principe ergodique en la considérant égale à `1"/"2` dans ce cas.
`P(x"/"y)=(P(x "et" y))/(P(y))`
Si la probabilité de `x` sachant `y` est égale à la probabilité de `x`, cela signifie que les deux évènements `x` et `y` sont indépendants. Les cinq propositions suivantes sont équivalentes :
`{x,y}` indépendant
`P(x"/"y)=(P(x "et" y))/(P(y))`
`P(y"/"x)=(P(x "et" y))/(P(x))`
`P(x "et" y)=P(x)"*"P(y)`
`N"*"N(x "et" y)=N(x)"*"N(y)`
Autres règles simples à démontrer qui découle du dénombrement :
`P("¬"x) = 1-P(x)`
`P(x "et" y) + P(x "et" "¬"y) = P(x)`
`P(x"/"y)"*"P(y)+P(x"/¬"y)"*"P("¬"y) = P(x)`
Une probabilité à multiple conditions se ramène à une probabilité à une condition :
`P((x"/"y)"/"z) = P(x"/"(y "et" z))`
L'entropie `S(x)` est la quantité d'informations que représente la connaissance qu'une proposition `x` est vrai. Dans le cas où la probabilité est construite sur une base de configurations équiprobables, elle est égale à :
`S(x) = -log(P(x))`
Où le logarithme est en base `2` pour obtenir un nombre de bits. La quantité d'information que représente la connaissance d'une configuration précise `(x_1,x_2,x_3,...,x_n)` est le nombre de bits nécessaires pour mémoriser le `n`-uplet de booléens en question, c'est à dire `n` bits. C'est le nombre de bits nécessaire pour compter toute les configurations et qui permet ainsi de choisire la configuration voulue. La quantité d'information que représente la connaissance qu'une variable de base `x_1` soit vrai, est le nombre de bits nécessaire pour mémoriser la valeur `x_1`, c'est à dire `1` bits. C'est le nombre de bits nécessaire pour choisir parmi deux parties, l'ensemble des configurations où `x_1` est vrai, et l'ensemble des configurations où `x_1` est faux. `S(x_1) = -log(P(x_1))`.
Le calcul de la probabilité à partir de l'entropie s'obtient donc comme suit :
`P(x) = 2^(-S(x))`
---- 06 avril 2026 ----